I see we have a response to our last post. Thank you, highperformance, for showing an interest. For anyone who also stumbles on this blog, I'll just post the final update.
We completed the project. Although the results were far from what we hoped to achieve. Due to the exceedingly large number of neurons, the BLSTM is very slow. Also, after having it run for several days on end, it has yet to show any conclusive evidence of actually positively identifying phonemes.
We started this project as part of the seminary Speech Recognition; we have since handed in our paper and received a passing grade. Both Timo and myself considered investing more time into this project, possibly as a study project. However this did not fit into either of our curricula so far. That makes the project abandonware at this point.
The last version of the source code is available here:
www.haploid.nl/sr2k7/lstm-070620-1511.zip
I am not aware of any restrictions on the use of this code, so use at your leisure. This code comes as is, with very little documentation on its use.
Saturday, November 17, 2007
Friday, June 8, 2007
Moderate Cheers
We got the hang of the backpropagation formulas, with a little help of one of our professors, dr. W.A. Kosters, and were able to implement most of them. The one part we haven't implemented yet, updating of weights, we have a firm understanding of what we're supposed to put down.
Of course, our code is as yet mostly untested, and we won't be able to test it until the whole network is complete.
We've also selected a subset of 380 utterances from the TIMIT corpus and identified 341 of them which aren't corrupted after conversion.
Remaining tasks:
Of course, our code is as yet mostly untested, and we won't be able to test it until the whole network is complete.
We've also selected a subset of 380 utterances from the TIMIT corpus and identified 341 of them which aren't corrupted after conversion.
Remaining tasks:
- Select files to use from TIMIT
- Convert WAV files
- Matlab code for extracting features from WAV files
- Matlab code for writing features into feature files
- C++ code for reading feature files
- C++ code for reading TIMIT annotation files
- C++ code object skeleton for BLSTM
- C++ code for forward propagation
- C++ code for back propagation
- C++ code for BLSTM trainer
- C++ code for BLSTM tester
- C++ code for serializing BLSTM
- Training the network on selected files
- Testing the network on selected files
- Write report
Thursday, June 7, 2007
Serialization
Short status update: serialization of the network has been implemented and tested.
Remaining tasks:
Remaining tasks:
- Select files to use from TIMIT
- Convert WAV files
- Matlab code for extracting features from WAV files
- Matlab code for writing features into feature files
- C++ code for reading feature files
- C++ code for reading TIMIT annotation files
- C++ code object skeleton for BLSTM
- C++ code for forward propagation
- C++ code for back propagation
- C++ code for BLSTM trainer
- C++ code for BLSTM tester
- C++ code for serializing BLSTM
- Training the network on selected files
- Testing the network on selected files
- Write report
Lower Case Sigma
Still, our main obstacle in the project is implementing back propagation. We've identified a few articles that describe the process best and provide the right formulas we need to reproduce it in our code. Currently, we're working with Long Short-Term Memory (Hochreiter & Schmidhueber, 1997). The article is extremely long, covers a lot of design choices for the LSTM, and most importantly, the appendix features all the formula's we'd need in a clear package.
We've come to the point that we understand how back propagation through time unrolls the network, and how each time step affects the time step before it. We were able to implement back propagation for the regular neurons in the network, the CEC, and the output gates. Unfortunately, we do not understand the formula's used for calculating the error/delta for the input gates and the forget gates (A.23 through A.26).
These formula's feature a symbol, the lower case sigma, that we're unsure how to read. As far as we're able to determine, the lower case sigma is only used in math to denote the standard deviation. Standard deviation does not seem appropriate in this formula.
We've come to the point that we understand how back propagation through time unrolls the network, and how each time step affects the time step before it. We were able to implement back propagation for the regular neurons in the network, the CEC, and the output gates. Unfortunately, we do not understand the formula's used for calculating the error/delta for the input gates and the forget gates (A.23 through A.26).
These formula's feature a symbol, the lower case sigma, that we're unsure how to read. As far as we're able to determine, the lower case sigma is only used in math to denote the standard deviation. Standard deviation does not seem appropriate in this formula.
Task Division
About time for a status update on the project. My apologies for not posting regularly. We've been doing a lot of coding, and the small victories/defeats you encounter while coding don't usually seem worth posting about.
We've divided the project into the following tasks:
The main problem areas at the moment are back propagation and selecting the WAV files to be used.
You may wonder what could possibly be so difficult about selecting files. Well, the TIMIT corpus consists of a non-regular type of WAV files, the NIST format type. Our Matlab code was tuned to use PCM WAV files. We've been able to find a good tool that converts the NIST files into usable PCM files, called sox. Conversion seems to work fine. The majority of converted files sound like we expect them to sound. A few, seemingly randomly determined, files are corrupt after conversion, garbled noise. We can't be sure whether this is a problem caused by the conversion or some problem in the file that is converted, since we are unable to listen to the original.
We've divided the project into the following tasks:
- Select files to use from TIMIT
- Convert WAV files
- Matlab code for extracting features from WAV files
- Matlab code for writing features into feature files
- C++ code for reading feature files
- C++ code for reading TIMIT annotation files
- C++ code object skeleton for BLSTM
- C++ code for forward propagation
- C++ code for back propagation
- C++ code for BLSTM trainer
- C++ code for BLSTM tester
- C++ code for serializing BLSTM
- Training the network on selected files
- Testing the network on selected files
- Write report
The main problem areas at the moment are back propagation and selecting the WAV files to be used.
You may wonder what could possibly be so difficult about selecting files. Well, the TIMIT corpus consists of a non-regular type of WAV files, the NIST format type. Our Matlab code was tuned to use PCM WAV files. We've been able to find a good tool that converts the NIST files into usable PCM files, called sox. Conversion seems to work fine. The majority of converted files sound like we expect them to sound. A few, seemingly randomly determined, files are corrupt after conversion, garbled noise. We can't be sure whether this is a problem caused by the conversion or some problem in the file that is converted, since we are unable to listen to the original.
Thursday, April 26, 2007
Backpropagation through time
The pace of development has picked up. We've been writing a lot of code, mostly skeleton code for the BLSTM algorithm.
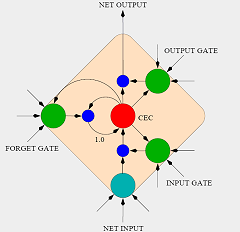
The BLSTM features two LSTM subnetworks, one of which reads the downstream context for the current frame and the other reads the upstream context. The context consists of a given number of frames. Using both downstream and upstream data allows the BLSTM to take advantage of information both forward and back in time. The output from the two context LSTM's and the current frame itself are then fed into a regular feed-forward network.
We've fully implemented the feed-forward network and laid down the skeleton for the LSTM subnetworks.
It took some reading to figure out the topology of the LSTM subnetworks. We believe the article that is our main focus for this project ( here ) implies that all gates are connected to all input nodes and to the output of each memory cell in the same layer. Similar articles have made contradictory statements. We opt to go with this choice.
At present, we are trying to figure out how backpropagation (and to a lesser degree forwardpropagation) in the LSTM works. Graves e.a. had this to say about it:
Also, the workings of BPTT (Backpropagation Through Time) are far from clear to us. There are plenty of articles on the subject on the internet, but we have yet to stumble on the one that describes the algorithm in understandable terms. Articles that show some promise of helping us get to grips are:
http://svr-www.eng.cam.ac.uk/~ajr/rnn4csr94/node14.html
http://page.mi.fu-berlin.de/~rojas/neural/chapter/K7.pdf
The BLSTM features two LSTM subnetworks, one of which reads the downstream context for the current frame and the other reads the upstream context. The context consists of a given number of frames. Using both downstream and upstream data allows the BLSTM to take advantage of information both forward and back in time. The output from the two context LSTM's and the current frame itself are then fed into a regular feed-forward network.
We've fully implemented the feed-forward network and laid down the skeleton for the LSTM subnetworks.
It took some reading to figure out the topology of the LSTM subnetworks. We believe the article that is our main focus for this project ( here ) implies that all gates are connected to all input nodes and to the output of each memory cell in the same layer. Similar articles have made contradictory statements. We opt to go with this choice.
At present, we are trying to figure out how backpropagation (and to a lesser degree forwardpropagation) in the LSTM works. Graves e.a. had this to say about it:
Starting at time t1, propagate the output errors backwards through the unfolded net, using the standard BPTT equations for a softmax output layer and the crossentropy error function.There's a number of things we're not sure about at this time. Mostly we don't know exactly what is referred to as the unfolded net. We assume this refers in some way to storing the activations of all nodes for all times while forwardpropagating.
Also, the workings of BPTT (Backpropagation Through Time) are far from clear to us. There are plenty of articles on the subject on the internet, but we have yet to stumble on the one that describes the algorithm in understandable terms. Articles that show some promise of helping us get to grips are:
http://svr-www.eng.cam.ac.uk/~ajr/rnn4csr94/node14.html
http://page.mi.fu-berlin.de/~rojas/neural/chapter/K7.pdf
Tuesday, April 17, 2007
Presentation April 18th
The presentation of our project is due tomorrow at the LIACS. In this presentation, we set out our goals and how we intend to tackle them. The presentation in itself is not a fully readable text, but if you're interested you can download it here.
- Timo
- Timo
Subscribe to:
Posts (Atom)