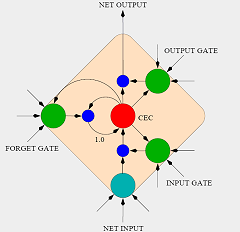
Of course, our code is as yet mostly untested, and we won't be able to test it until the whole network is complete.
We've also selected a subset of 380 utterances from the TIMIT corpus and identified 341 of them which aren't corrupted after conversion.
Remaining tasks:
- Select files to use from TIMIT
- Convert WAV files
- Matlab code for extracting features from WAV files
- Matlab code for writing features into feature files
- C++ code for reading feature files
- C++ code for reading TIMIT annotation files
- C++ code object skeleton for BLSTM
- C++ code for forward propagation
- C++ code for back propagation
- C++ code for BLSTM trainer
- C++ code for BLSTM tester
- C++ code for serializing BLSTM
- Training the network on selected files
- Testing the network on selected files
- Write report