Welcome to our blog!
We are Timo de Vries and Jasper A. Visser, students at the Leiden Institute of Advanced Computer Science (LIACS). As part of the seminar Speech Recognition, we are implementing a neural network solution to classify phonemes from speech input.
Specifically, we have chosen to use a Long Short-Term Memory recurrent network, which has been proven to do well in this particular area. Over the course of the next months, we will be updating this blog with articles we have found to be useful, progress updates on our project, and other useful information.
- Jasper
Thursday, April 12, 2007
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
For the Speech Recognition seminar, we have read some articles about phoneme recognition. The above article gave us the idea to build a Long Short Term Memory network that can be trained to classify phonemes accurately.
The article can be found here.
- Timo
In this paper, we present bidirectional Long Short Term Memory (LSTM) networks, and a modified, full gradient version of the LSTM learning algorithm. We evaluate Bidirectional LSTM (BLSTM) and several other network architectures on the benchmark task of framewise phoneme classification, using the TIMIT database. Our main findings are that bidirectional networks outperform unidirectional ones, and Long Short Term Memory (LSTM) is much faster and also more accurate than both standard Recurrent Neural Nets (RNNs) and time-windowed Multilayer Perceptrons (MLPs). Our results support the view that contextual information is crucial to speech processing, and suggest that BLSTM is an effective architecture with which to exploit it.
The article can be found here.
- Timo
Learning to Forget: Continual Prediction with LSTM
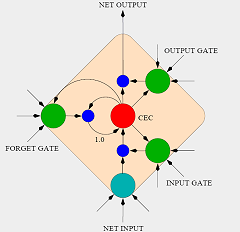
Another excellent article on the subject of LSTM's, written by Gers, Schmidhuber & Cummins, addresses the problem of saturation of the CEC of a memory cell and how it can be combatted using forget gates.
There's plenty of math included, which will be very helpful for our own implementation. The article also describes the topology of the network used in the test setup. Previously read articles were not too clear about exactly which units were connected to the input & output gates.
Click here for the full text
- Jasper
Long short-term memory (LSTM; Hochreiter & Schmidhuber, 1997) can solve numerous tasks not solvable by previous learning algorithms for recurrent neural networks (RNNs). We identify a weakness of LSTM networks processing continual input streams that are not a priori segmented into subsequences with explicitly marked ends at which the network's internal state could be reset. Without resets, the state may grow indefinitely and eventually cause the network to break down. Our remedy is a novel, adaptive "forget gate" that enables an LSTM cell to learn to reset itself at appropriate times, thus releasing internal resources. We review illustrative benchmark problems on which standard LSTM outperforms other RNN algorithms. All algorithms (including LSTM) fail to solve continual versions of these problems. LSTM with forget gates, however, easily solves them, and in an elegant way.
There's plenty of math included, which will be very helpful for our own implementation. The article also describes the topology of the network used in the test setup. Previously read articles were not too clear about exactly which units were connected to the input & output gates.
The seven input units are fully connected to a hidden layer consisting of four memory blocks with 2 cells each (8 cells and 12 gates in total). The cell outputs are fully connected to the cell inputs, all gates, and the seven output units. The output units have additional "shortcut" connections from the input units.
Click here for the full text
- Jasper
Subscribe to:
Posts (Atom)